Chef Infra Client Overview
Note
chef-client command line tool, see
chef-client(executable) The Chef Infra Client
executable can be run as a daemon.
| Chef Infra Client is an agent that runs locally on every node that is under management by Chef Infra Server. When Chef Infra Client runs, performs all of the steps required for bringing a node into the expected state, including:
|
The Chef Infra Client Run
A “Chef Infra Client run” is the term used to describe the steps Chef Infra Client takes to configure a node during a run. The following diagram shows the various stages that occur during a Chef Infra Client run.
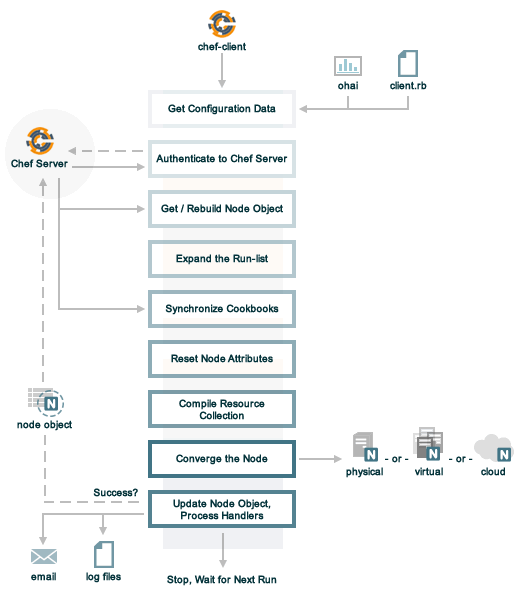
During every Chef Infra Client run, the following happens:
| Stages | Description |
|---|---|
| Get configuration data | Chef Infra Client gets process configuration data from the client.rb file on the node, and then gets node configuration data from Ohai. One important piece of configuration data is the name of the node, which is found in the node_name attribute in the client.rb file or is provided by Ohai. If Ohai provides the name of a node, it is typically the FQDN for the node, which is always unique within an organization. |
| Authenticate to the Chef Infra Server | Chef Infra Client authenticates to the Chef Infra Server using an RSA private key and the Chef Infra Server API. The name of the node is required as part of the authentication process to the Chef Infra Server. If this is the first Chef Infra Client run for a node, the chef-validator will be used to generate the RSA private key. |
| Get, rebuild the node object | Chef Infra Client pulls down the node object from the Chef Infra Server. If this is the first Chef Infra Client run for the node, there will not be a node object to pull down from the Chef Infra Server. After the node object is pulled down from the Chef Infra Server, Chef Infra Client rebuilds the node object. If this is the first Chef Infra Client run for the node, the rebuilt node object will contain only the default run-list. For any subsequent Chef Infra Client run, the rebuilt node object will also contain the run-list from the previous Chef Infra Client run. |
| Expand the run-list | Chef Infra Client expands the run-list from the rebuilt node object, compiling a full and complete list of roles and recipes that will be applied to the node, placing the roles and recipes in the same exact order they will be applied. (The run-list is stored in each node object's JSON file, grouped under run_list.) |
| Synchronize cookbooks | Chef Infra Client asks the Chef Infra Server for a list of all cookbook files (including recipes, templates, resources, providers, attributes, libraries, and definitions) that will be required to do every action identified in the run-list for the rebuilt node object. The Chef Infra Server provides to Chef Infra Client a list of all of those files. Chef Infra Client compares this list to the cookbook files cached on the node (from previous Chef Infra Client runs), and then downloads a copy of every file that has changed since the previous Chef Infra Client run, along with any new files. |
| Reset node attributes | All attributes in the rebuilt node object are reset. All attributes from attribute files, environments, roles, and Ohai are loaded. Attributes that are defined in attribute files are first loaded according to cookbook order. For each cookbook, attributes in the default.rb file are loaded first, and then additional attribute files (if present) are loaded in lexical sort order. If attribute files are found within any cookbooks that are listed as dependencies in the metadata.rb file, these are loaded as well. All attributes in the rebuilt node object are updated with the attribute data according to attribute precedence. When all of the attributes are updated, the rebuilt node object is complete. |
| Compile the resource collection | Chef Infra Client identifies each resource in the node object and builds the resource collection. Libraries are loaded first to ensure that all language extensions and Ruby classes are available to all resources. Next, attributes are loaded, followed by custom resources, and then all definitions (to ensure that any pseudo-resources within definitions are available). Finally, all recipes are loaded in the order specified by the expanded run-list. This is also referred to as the "compile phase". |
| Converge the node | Chef Infra Client configures the system based on the information that has been collected. Each resource is executed in the order identified by the run-list, and then by the order in which each resource is listed in each recipe. Each resource in the resource collection is mapped to a provider. The provider examines the node, and then does the steps necessary to complete the action. And then the next resource is processed. Each action configures a specific part of the system. This process is also referred to as convergence. This is also referred to as the "execution phase". |
Update the node object, process exception and report handlers | When all of the actions identified by resources in the resource collection have been done and Chef Infra Client finishes successfully, then Chef Infra Client updates the node object on the Chef Infra Server with the node object built during a Chef Infra Client run. (This node object will be pulled down by Chef Infra Client during the next Chef Infra Client run.) This makes the node object (and the data in the node object) available for search. Chef Infra Client always checks the resource collection for the presence of exception and report handlers. If any are present, each one is processed appropriately. |
| Stop, wait for the next run | When everything is configured and the Chef Infra Client run is complete, Chef Infra Client stops and waits until the next time it is asked to run. |